Introduction
In radiation therapy for breast cancer patients, numerous clinical factors are considered. For instance, when the National Comprehensive Cancer Network panels [1] recommend comprehensive regional nodal irradiation for pN1 patients, it also recommends considering clinical factors such as whether the primary tumor is small or there is only one metastasis. Indeed, clinical decision to irradiate full regional lymph nodes or not depend on clinical factors including age, nuclear grade, molecular subtype, resection margin status, lymphovascular invasion and extranodal extension [2–5] as well as TNM stage. Thus, pathologic factors and radiologic findings are carefully reviewed to make an optimal decision in clinical practice. Radiation oncologists manually reviewed the medical record of each patient, seeking important factors to support their decision. When collecting clinical information for research work, medical reports are thoroughly reviewed, factors are manually classified, and the case report form is constructed. This process is labor-intensive, costly, and time-consuming. However, automation of these processes has been challenging due to difficulties in processing unstructured, narrative-style reports generated from diagnostic work-up for breast cancer patients.
Recent advances in natural language processing (NLP) play a pivotal role in solving complex problems like the challenges mentioned above. NLP makes it possible to reliably extract important information from free text, and many fields of medicine, including radiation oncology, could benefit from these techniques [6]. In the field of NLP, state-of-the-art large language models (LLMs) like GPT-4 (Generative Pre-trained Transformer 4) have shown outstanding abilities in understanding and generating human language [7]. This enables LLMs to comprehend textual data and establish contextual connections, leading to revolutionary achievements. Further, this capability allows LLMs to analyze complex medical data, extract crucial information, and support decision-making. As such, the effective utilization of LLMs offers tremendous potential in the automation of traditional medical chart review.
To use LLM effectively, “prompts” must be properly developed. Prompts are input sentences or phrases for LLM to perform a specific action. The content and structure of these prompts greatly influence the output and performance of LLMs [8]. Depending on the prompt, LLM model determine which information to process and what type of answers to generate. Thus, design of proper prompts is key to maximizing the capabilities of LLMs, given that inappropriate prompts can cause models to misunderstand or produce unexpected results. In particular, in the field of radiation oncology, research on prompt engineering is required for LLM to extract accurate information from unstructured medical reports.
In this study, prompts were developed to extract the required information using LLM from surgical pathology reports and preoperative ultrasound reports of breast cancer patients. The time and cost needed to develop the prompt was assessed and compared with manual methods. Also, the accuracy of the extracted information was evaluated by comparing it with information collected manually.
Materials and Methods
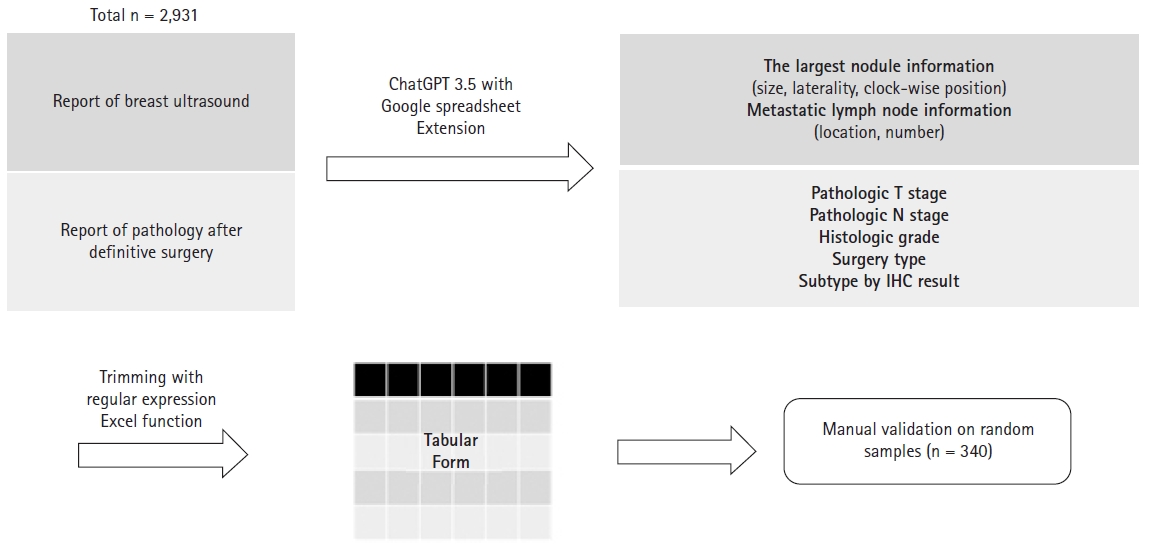
We collected data from breast cancer patients who received postoperative radiotherapy (RT) from 2020 to 2022 in our institution. Male breast cancer patients, patients who received palliative RT, and patients who did not undergo surgery at our institution were excluded. For the study population, the findings from the earliest breast ultrasound within one year before the surgery and the report from surgical pathology were collected. The overall study schema is depicted in Fig. 1.
As the target LLM, we selected the ChatGPT and accessed it with an extension program of Google Sheets, named as GPT for Sheets and Docs (https://gptforwork.com). This plugin, developed by Talarian, is an application that allows the GPT model to be used directly in Google Sheets and provides additional custom features. This makes using various LLM models such as GPT3 and ChatGPT models in Google Sheets possible. In this study, we used the ChatGPT (gpt-3.5-turbo) model.
From the ultrasound reports, prompts were designed to extract and organize factors related to the clinical stage. To determine the clinical T stage, we designed prompts to extract the size and location of the largest suspected cancerous mass within the breast. To extract information about the clinical N stage, we designed prompts to extract the number of suspected metastatic lymph nodes for each nodal area. In addition, information about laterality and tumor location was also extracted.
In the surgical pathology report, prompts were designed to extract factors like tumor size and number of metastatic lymph nodes, which determines the pathological stage. We also designed prompts to extract clinical factors such as histologic grade, neoadjuvant chemotherapy status, resection margin status, molecular subtype, lymphovascular invasion, and extracapsular extension. In addition, we designed prompts to extract factors, such as surgery type and metastatic lymph node ratio.
To evaluate the efficiency and accuracy of the extraction method using LLM, we compared three methods of collecting clinical information from medical records. First, the “full manual” method was done by JYS, a resident physician in Radiation Oncology. The method is a way to manually collect information from the medical records of each patient, and to ensure 100% accuracy, the information was verified by another physician after collection. Second, the “LLM-assisted manual” method was done by the same resident physician who did the “full manual” method, but with the assistance of the information already collected using LLM. Lastly, the “LLM” method used LLM alone to extract information of clinical factors. To establish comparability throughout the three methods, 340 patients, were randomly selected using the RAND function in Microsoft Excel to extract information. We calculated the sample size to represent the accuracy of the entire 2,913 cases with a confidence level of 95% and a margin of error of 5%.
The accuracy and time- and cost-efficiency were assessed using the following methods. First, the accuracy of the “LLM” method was assessed by regarding the information collected by the “full manual” method as the ground truth and comparing the data collected with both methods. The accuracy rate was calculated by each factor. Also, the time spent to collect the information, to design prompts, or to trim information collected by LLM was measured. Since only 340 patients were included in “full manual” and ‘LLM-assisted manual’ methods, a factor of 8.57 (2,931/340) was multiplied by the measured time to extrapolate, and establish comparability between the three methods. Furthermore, the cost spent to collect the information was estimated. In the “full manual” and “LLM-assisted manual” methods, the cost was estimated by multiplying the measured time by US $7.4 per hour, which is South Korea’s minimum wage in 2023. In the “LLM-assisted manual” and “LLM” methods, the estimated cost for prompt design and the GPT application programming interface (API) fee was measured. Since the “LLM” method was performed on entire patients, the cost for 340 patients was calculated by dividing the total GPT API fee by 8.57.
Results
In total, 2,931 breast cancer patients treated at our institution were included in this study. Table 1 shows the factors, function types, prompts designed, and their corresponding results in this study. A representative example of a surgical pathology report and an ultrasound report could be found in Supplementary Figs. S1 and S2.
Prompts were developed using the Extract function and the Format function from GPT for Sheets and Docs. The Extract function extracts the required information from the reports. The Format function was used to convert them into a structured format. For future statistical analysis, it is essential to standardize the format of responses. Therefore, the choice or type of response was predetermined through the prompts. When the required information could not be extracted at once, the extraction was performed in two steps. For example, when the information regarding the largest nodule among the nodes with suspected malignancy is needed, the information of the node that corresponds to the condition is first extracted, and then the information on diameter, laterality, and clockwise location is extracted again from that extracted information.
In some cases, simple computations to trim the extracted information were necessary. These were performed using IF, AND, and OR functions in Microsoft Excel. For instance, functions were used to determine the breast cancer subtype based on immunohistochemistry results or to identify whether the breast cancer was located on the inner or outer side based on the laterality and clockwise location. When additional trimming was needed for statistical analysis, the information was trimmed using regular expressions in Python.
The accuracy of the information extraction by LLM was calculated by each factor and is shown in Table 2. Regarding all the factors, the average accuracy was 87.7%, which could be translated to roughly 298 out of 340 patients. Among all factors, lymphovascular invasion had the highest accuracy of 98.2%. In contrast, neoadjuvant chemotherapy status and tumor location had the lowest accuracy of 47.6% (162 out of 340) and 63.8% (217 out of 340), respectively.
The time- and cost-efficiency of the information extraction by LLM were also assessed. Regarding the time-efficiency, it took 1.5 hours for designing the prompts for the ultrasound report and 2 hours for the surgical pathology report. Responses to the prompts were outputted in parallel for each cell in the table via the GPT server. The entire response output process took 15 minutes. Trimming the data took approximately 30 minutes in total, which was mostly coding time, and the actual application was completed in a few seconds. In total, approximately 4 hours were needed in extracting clinical factors from 2,931 breast cancer patients. In terms of cost, using the GPT model through the GPT API incurs a fee per token. In the current study, US $6.04 for ultrasound interpretation and US $59.76 for surgical pathology interpretation was charged using the GPT API, for a total of US $65.8. Also, the whole process took 4 hours to design the prompts and trim the data, which could be translated to a wage cost of US $29.6, when applying the minimum wage of South Korea in 2023. The response output process was excluded from the wage cost calculation because the process could be done automatically.
The time and cost spent on collecting the information using “full manual,” “LLM-assisted manual,” and “LLM” methods were measured and estimated for comparison (Table 3). For all 2,913 patients, the time spent for the “full manual,” “LLM-assisted manual,” and “LLM” methods were 122.6 hours, 79.4 hours, and 4 hours, respectively. The estimated cost for “full manual,” “LLM-assisted manual,” and “LLM” methods were US $909.3, $653.4, and $95.4, respectively. By using “LLM-assisted manual” and “LLM” methods compared to the “full manual” method, we could save 43.2 hours and US $255.9, and 118.6 hours and US $813.9 in all 2,913 patients, respectively.
Discussion and Conclusion
In the current study, we investigated the efficiency and accuracy of the utilization of LLM in extracting RT-related factors. From 2,931 breast cancer patients, we extracted clinical factors from the reports of ultrasound and surgical pathology. The whole process took 4 hours and cost US $95.4, and the average accuracy was 87.7%.
The GPT model, which is employed in the current study, is intended to imitate natural conversations, and does not contain logical thinking [9]. Thus, it does not understand the meaning of sentences but is merely aligning the most likely word to use. In other words, there is no logic in the response it gives. For example, in the current study, we first wanted to separate the location of a breast tumor into inner and outer based on laterality and the clockwise direction from the nipple. Despite many trials and errors, we failed to implement the function in a GPT model. This may be because the GPT model failed to comprehend the logic that the clockwise direction is opposite according to the laterality of the breast in separating inner from outer lesions. Also, another well-known feature of the GPT model is a phenomenon called the hallucination [10]. This is a phenomenon that the model responds with a plausible answer that is incorrect. For example, when the GPT-3.5 is asked “Explain to me the clinical N stage of breast cancer according to the American Joint Committee on Cancer (AJCC) 8th edition,” it comes up with a plausible answer which is an explanation about the pathological N stage. The hallucination was seen time to time in extracting information in the current study. For example, when asked about the diameter of the tumor from the ultrasound report, it sometimes responded with the distance from the nipple. We speculate that this hallucination occurred because the two values are both written in numerical values in centimeter. In another example, the category “Neoadjuvant chemotherapy” was accurate at less than 50%. It could be due to hallucination. Even though there was no information about neoadjuvant chemotherapy in the pathology report, LLM gave a yes or no answer instead of saying that there was insufficient information. A deep understanding in such features of LLMs is crucial to designing prompts and applying it to use.
Developing an effective prompt to get the desired outcome, which is called prompt engineering, is the most crucial point in utilizing LLM. In prompt engineering, the features of LLMs should be well understood by developers. When using an LLM, users may avoid using jargon, instead, should provide all the information needed to generate a response. Also, it is recommended to write the logic leading up to the desired outcome in the prompt, rather than trying to achieve the desired outcome all at once, thereby, the LLM can follow the logical process. For example, in interpreting an ultrasonography report, instead of saying, “Identify the clinical T stage,” it is better to say, “Here's an ultrasound reading of a breast cancer patient, find the mass with the largest diameter and tell me its diameter in centimeters.” Also, these results can be improved with a well-known few-shot learning or fine-tuning method by introducing an example within the prompt and having the LLM replicate the logical flow [11]. Since we could not fully predict the output of LLM, it is essential to modify and correct the prompt through a trial-and-error method, rather than completing it at once. Understanding these features will provide appropriate answers to users when effective prompt engineering is adopted in coding clinical data.
Information extraction by developing prompts from LLM is extremely efficient in terms of both time and expenses, especially when it is applied to a task handling huge data. From raw data of thousand patients to well-organized spreadsheet data, we could save 118.6 hours and US $813.9 by using “LLM” method. After completing the prompt design, the cost of developing the prompt is fixed, which could save expenses for research that needs to be encoded from large data, such as pathological or radiographic findings of patients with breast or prostate cancer treated with radiation therapy. This method is a much-awaited in labor market like South Korea, where the hiring of qualified healthcare provider is expensive and scarce. For the last decade in South Korea, there has been a steep growth in wages with the minimum wage almost doubling [12], and that of the healthcare providers are no exception [13]. In addition, the “Act on the Improvement of Training Conditions and Status of Medical Residents” was enacted in 2015, restricting the working hours of medical residents [14]. Due to advantage of the using LLM in large-scale tasks, development, and facilitating prompts are employed in other expert fields as well [15].
The accuracy of the information extracted by prompts using LLM was 87.7%, which is an encouraging result compared to conventional NLP models. Juhn et al. [16] reported 80%–98% accuracy in identifying the presence or severity of allergic conditions through medical record review using an NLP-based model [16]. In addition, Tang et al. [17] reported a low accuracy of 23.4% in biomedical named entity recognition using the ChatGPT, and a higher accuracy of 75.9% in LLM for medical tasks. Although the accuracy of 87.7% in the current study is notable, it should be cautioned to use without supervision. Manual examination should be done to re-examine the extracted information. Alternatively, a hybrid method that we named the “LLM-assisted manual” method could be a reasonable way to compromise in a real-world setting. By referring to the information extracted, one can collect information more efficiently, while still maintaining the level of accuracy of a manual information collection. Recently, the GPT-4 was released and expected to reduce the frequency of hallucinations and improve accuracy [7]. We expect that LLMs specialized in medical tasks may elevate the accuracy of extraction even better [18,19].
There were several limitations in this study. First, the clinical N stage did not strictly follow the AJCC staging system. The information in the ultrasound report was insufficient to extract whether a lymph node is movable or not. Thus, distinguishing between clinical N1 and N2 solely depended on the number of nodal metastasis or the presence of an internal mammary lymph node metastasis without axillary metastasis, and has discrepancy with the AJCC staging system. Also, the “full manual” method, which is used as a ground truth, is not perfect. Although manual process is the control for the “LLM” process, the “full manual” method does not guarantee 100% accuracy in information collection due to the human error. It could be improved if two or more people could cross-check each other’s collected information to approach 100% accuracy for a solid ground truth. Moreover, using minimum wage in the evaluation of total cost may be inaccurate. Healthcare providers such as doctors or nurses, who would likely collect the clinical information from the medical records in real-life, receive more than a minimum wage. Therefore, the exact cost of manual information collection could be higher. Finally, the extrapolation of time and cost taken in 60 patients into 2,913 patients may be inaccurate. Validation with more data is required.
In conclusion, we showed that using LLM prompts is an efficient way to extract crucial information from the medical records of breast cancer patients and to construct well-fined clinical data. This method is expected to save lots of effort from daily practice and research work. Prompts from the current study can be re-used for other investigators to collect clinical information.